The lesson will consider the sql query language: the basics of the syntax of the sql language, work in phpMyAdmin and a service for online checking sql queries
Database- centralized data storage providing storage, access, primary processing and information retrieval.
Databases are divided into:
SQL (Structured Query Language)- is a structured query language (translated from English). The language is focused on working with relational (tabular) databases. The language is simple and, in fact, consists of commands (interpreted), through which you can work with large amounts of data (databases), deleting, adding, changing information in them and performing a convenient search.
To work with SQL code, you need a database management system (DBMS), which provides functionality for working with databases.
Database management system(DBMS) - a set of language and software tools designed for the creation, maintenance and sharing of a database by many users.
Usually, for training, it is used Microsoft Access DBMS, but we will use a more common system in the web sphere -. For convenience, it will use a web interface or an online service to build sql queries, the principle of work with which is described below.
Important: When working with relational or tabular databases, the table rows will be called records and the columns are margins.
Each column must have its own data type, i.e. should be designed to enter data of a specific type. are described in one of the lessons in this course.
The SQL language consists of the following components:
1.
The data manipulation language consists of 4 main commands:
Data Definition Language is used to create and modify the structure of the database and its constituent parts - tables, indexes, views (virtual tables), as well as triggers and stored procedures.
We will consider only a few of basic language commands... They are:
Data Management Language is used to manage access rights to data and execution of procedures in a multi-user environment.
First you need to complete the first two points from.
Then:

Online checking of sql queries is possible using the service.
The easiest way to organize work consists of the following steps:

Another example: 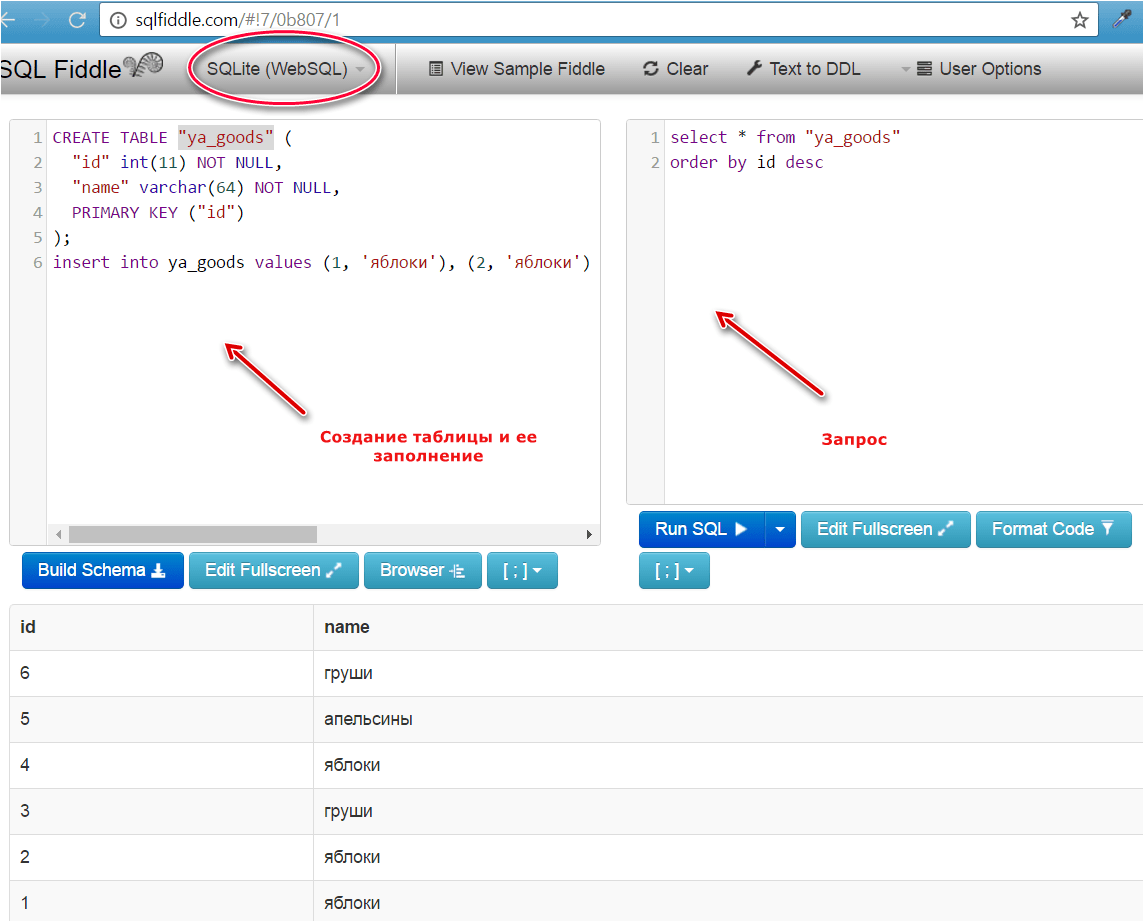
Now we will consider some points in more detail.
Creating tables:
Example: create three tables at once (teachers, lessons and courses); add multiple values to each table.
* for those who are not familiar with the syntax - just copy the entire code and paste it into the left window of the service
* a lesson on creating tables in SQL
| / * teachers * / CREATE TABLE `teachers` (` id` INT (11) NOT NULL, `name` VARCHAR (25) NOT NULL,` code` INT (11), `zarplata` INT (11),` premia` INT (11), PRIMARY KEY (`id`)); INSERT INTO teachers VALUES (1, "Ivanov", 1, 10000, 500), (2, "Petrov", 1, 15000, 1000), (3, "Sidorov", 1, 14000, 800), (4, " Bobrova ", 1, 11000, 800); / * lessons * / CREATE TABLE `lessons` (` id` INT (11) NOT NULL, `tid` INT (11),` course` VARCHAR (25), `date` VARCHAR (25), PRIMARY KEY (` id `)); INSERT INTO lessons VALUES (1, 1, "php", "2015-05-04"), (2, 1, "xml", "2016-13-12"); / * courses * / CREATE TABLE `courses` (` id` INT (11) NOT NULL, `tid` INT (11),` title` VARCHAR (25), `length` INT (11), PRIMARY KEY (` id `)); INSERT INTO courses VALUES (1, 1, "php", 54), (2, 1, "xml", 72), (3, 2, "sql", 25); |
/ * teachers * / CREATE TABLE `teachers` (` id` int (11) NOT NULL, `name` varchar (25) NOT NULL,` code` int (11), `zarplata` int (11),` premia` int (11), PRIMARY KEY (`id`)); insert into teachers values (1, "Ivanov", 1,10000,500), (2, "Petrov", 1,15000,1000), (3, "Sidorov", 1,14000,800), (4, " Bobrov ", 1,11000,800); / * lessons * / CREATE TABLE `lessons` (` id` int (11) NOT NULL, `tid` int (11),` course` varchar (25), `date` varchar (25), PRIMARY KEY (` id `)); insert into lessons values (1,1, "php", "2015-05-04"), (2,1, "xml", "2016-13-12"); / * courses * / CREATE TABLE `courses` (` id` int (11) NOT NULL, `tid` int (11),` title` varchar (25), `length` int (11), PRIMARY KEY (` id `)); insert into courses values (1,1, "php", 54), (2,1, "xml", 72), (3,2, "sql", 25);
As a result, we get tables with data: 
Sending a request:
In order to test the serviceability, add the request code to the right window.
Example: use a query to select all data from the teachers table for the teacher with the last name Ivanov
In further SQL lessons, the same schema will be used, so you just need to copy the schema and paste it into the left window of the service.
For online visualization of the database schema, you can use the service https://dbdesigner.net/:

Programming on T- SQL
T-SQL Syntax and Conventions
Rules for the formation of identifiers
All objects in SQL Server have names (identifiers). Examples of objects are tables, views, stored procedures, etc. Identifiers can be up to 128 characters long, such as letters, _ @ $ # symbols, and numbers.
The first character must always be alphabetic. Special naming schemes are used for variables and temporary tables. The object name cannot contain spaces and cannot match the SQL Server reserved keyword, regardless of the case used. You can use illegal characters in object names by enclosing identifiers in square brackets.
Completion of instructions
ANSI SQL requires a semicolon at the end of each statement. However, when programming in T-SQL, the semicolon is optional.
Comments (1)
T-SQL accepts two comment styles: ANCI and C. The first one starts with two hyphens and ends at the end of the line:
This is an ANSI style one line comment
Also, ANSI style comments can be inserted at the end of a statement line:
SELECT CityName - retrieved columns
FROM City - source table
WHERE IdCity = 1; - line constraint
The SQL editor can apply and remove comments on all selected lines. To do this, select the appropriate commands in the menu Edit or on the toolbar.
C style comments begin with a forward slash and an asterisk (/ *) and end with the same characters in reverse order. This type of comment is best used to comment out blocks of lines such as headers or large test queries.
multi-line
comment
One of the great things about C-style comments is that you can run multi-line queries in them without even uncommenting.
T-SQL packages
A query is a single T-SQL statement, and a batch is a collection of them. The entire sequence of packet instructions is sent to the server from client applications as one integral unit.
SQL Server treats the entire package as a unit of work. The presence of an error in at least one instruction will lead to the impossibility of executing the entire package. At the same time, parsing does not check the names of objects and schemas, since the schema itself may change during the execution of the statement.
The SQL script file and the Query Analyzer window can contain multiple packages. In this case, all packages share terminator keywords. By default, this keyword is GO and must be the only one on the line. All other characters (even comments) negate the packet separator.
Debugging T-SQL
When the SQL editor encounters an error, it displays the nature of the error and the line number in the batch. By double-clicking on an error, you can immediately jump to the corresponding line.
The SQL Server 2005 Management Studio utility does not include the T-SQL debugger — it is included in the Visual Studio package.
SQL Server offers several commands to help you debug packages. In particular, the PRINT command sends a message without generating a result dataset. The PRINT command can be used to track the progress of a package. With the Query Analyzer in grid mode, run the following batch:
SELECT CityName
FROM City
WHERE IdCity = 1;
PRINT "Check Point";
The resulting dataset will be displayed in the grid and will be one row. At the same time, the following result will be displayed in the Messages tab:
(lines processed: 1)
Check Point
Variables
T-SQL variables are created using the DECLARE command, which has the following syntax:
DECLARE @ Variable_Name Data_type [,
@ Variable_Name Data_type, ...]
All local variable names must begin with @. For example, to declare a local variable UStr that stores up to 16 Unicode characters, you can use the following statement:
DECLARE @UStr varchar (16)
The data types used for the variables are exactly the same as those in the tables. Several variables can be listed in one DECLARE command, separated by commas. Specifically, the following example creates two integer variables a and b:
DECLARE
@a int,
@b int
Variables are only scoped (i.e. their lifetime) for the current package. By default, newly created variables contain null NULL values and must be initialized before being included in expressions.
Setting Variable Values
Currently, SQL provides two ways to set the value of a variable - for this purpose, you can use the SELECT or SET statement. In terms of their functionality, these statements work almost the same, except that the SELECT statement retrieves the original assignable value from the table specified in the SELECT statement.
The SET statement is commonly used to set the values of variables in a form that is more common in procedural languages. Typical examples of the use of this operator include the following:
SET @a = 1;
SET @b = @a * 1.5
Note that all of these operators directly perform assignments using either explicit values or other variables. You cannot use a SET statement to assign a value to a variable that is obtained from a query; the query must be executed separately, and only then can the resulting result be assigned using the SET statement. For example, an attempt to execute such a statement generates an error:
DECLARE @c int
SET @c = COUNT (*) FROM City
SELECT @c
and the following statement succeeds:
DECLARE @c int
SET @c = (SELECT COUNT (*) FROM City)
SELECT @c
The SELECT statement is typically used to assign values to variables when the source of the information to be stored in the variable is from a query. For example, the actions performed in the above code are much more often implemented using the SELECT statement:
DECLARE @c int
SELECT @c = COUNT (*) FROM City
SELECT @c
Please note that this code is a little clearer (in particular, it is more concise, although it does the same thing).
Thus, it is possible to formulate the following generally accepted agreement on the use of both operators.
The SET statement is used when a simple assignment to a variable is to be performed, i.e. if the assigned value has already been set explicitly in the form of a definite value or in the form of some other variable.
Using Variables in SQL Queries
One of the useful properties of the T-SQL language is that variables can be used in queries without the need to create complex dynamic strings that embed variables in the program code. Dynamic SQL continues to exist, but a single value can be changed more easily by using a variable.
Wherever an expression can be used in a query, a variable can also be used. The following example demonstrates the use of a variable in a WHERE clause:
DECLARE @IdProd int;
SET @IdProd = 1;
SELECT
FROM Product
WHERE IdProd = @IdProd;
Global system variables
SQL Server has over thirty global, parameterless variables that are defined and maintained by the system. All global variables are prefixed with two @ symbols. You can retrieve the value of any of them with a simple SELECT query, as in the following example:
SELECT @@ CONNECTIONS
It uses the @@ CONNECTIONS global variable to retrieve the number of connections to SQL Server since the program was started.
Some of the most commonly used system variables are:
! Note that since SQL Server 2000, global variables are referred to as functions. The name global confused users, suggesting that the scope of such variables is wider than that of local variables. The ability to store information, regardless of whether it is included in the package or not, was often mistakenly attributed to global variables, which, of course, did not correspond to reality.
Command flow controls. Software constructs
The T-SQL language provides most of the classic procedural tools for controlling the flow of program execution, incl. conditional construction and loops.
OperatorIF. ... ... ELSE
IF statements. ... .ELSE acts in T-SQL in much the same way as in any other programming language. The general syntax for this operator is as follows:
IF Boolean expression
SQL statement I BEGIN Block of SQL statements END
SQL statement | BEGIN SQL Block of END Statements]
Almost any expression can be specified as a logical expression, the result of which evaluates to a boolean value.
It should be borne in mind that only the statement that immediately follows the IF statement (closest to it) is considered to be executed by condition. Instead of one operator, you can provide for the execution of several operators by condition, combining them into a block of code using the BEGIN ... END construction.
In the example below, the IF condition is not met, which prevents the following statement from being executed.
IF 1 = 0
PRINT "First line"
PRINT "Second line"
The optional ELSE command allows you to specify a statement to be executed if the IF condition is not met. Like IF, an ELSE statement only controls the immediately following command or block of code between BEGIN ... END.
Although the IF statement looks limited, its condition clause can include powerful features like the WHERE clause. In particular, these are IF EXISTS () expressions.
The IF EXISTS () expression uses as a condition the existence of any row returned by the SELECT statement. Since any rows are searched, the list of columns in the SELECT statement can be replaced with an asterisk. This method is faster than checking the @@ ROWCOUNT> 0 condition because there is no need to count the total number of rows. As soon as at least one row satisfies the IF EXISTS () condition, the query can continue execution.
The following example uses the IF EXISTS expression to check if customer code 1 has any orders before deleting it from the database. If there is information on at least one order for this client, the deletion is not made.
IF EXISTS (SELECT * FROM WHERE IdCust = 1)
PRINT "It is impossible to delete the client because there are records associated with it in the database"
ELSE
WHERE IdCust = 1
PRINT "Deletion completed successfully"
OperatorsWHILE, BREAK andCONTINUE
The WHILE clause in SQL works in much the same way as it does in other languages that a programmer usually has to work with. In fact, in this statement, a certain condition is checked before the beginning of each pass through the loop. If, before the next pass through the loop, checking the condition results in a TRUE value, the loop is looped through, otherwise the statement is terminated.
The WHILE statement has the following syntax:
WHILE Boolean expression
SQL statement I
Block of SQL statements
Of course, with the WHILE statement, you can ensure that only one statement is executed in a loop (similar to how the IF statement is usually used), but in practice, WHILE constructs that are not followed by a BEGIN block. ... .END conforming to the full operator format is rare.
The BREAK statement allows you to immediately exit the loop, without waiting for the pass to the end of the loop to be performed and the conditional expression is re-checked.
The CONTINUE statement allows you to interrupt a single iteration of the loop. You can briefly describe the action of the CONTINUE statement so that it jumps to the beginning of the WHILE loop. As soon as the CONTINUE operator is found in the loop, regardless of where it is located, the loop goes to the beginning of the loop and the conditional expression is re-evaluated (and if the value of this expression is no longer TRUE, the loop is exited).
The following short script demonstrates the use of the WHILE clause to create a loop:
DECLARE @Temp int;
SET @Temp = 0;
WHILE @Temp< 3
BEGIN
PRINT @Temp;
SET @Temp = @Temp + 1;
Here, in the loop, the integer variable @Temp is incremented from 0 to 3, and its value is displayed on the screen at each iteration.
OperatorRETURN
The RETURN statement is used to stop the execution of a package, and therefore a stored procedure and trigger (covered in the next lab).
The SQL language is used to retrieve data from the database. SQL is a programming language that closely resembles English, but is designed for database management programs. SQL is used in every query in Access.
Understanding how SQL works helps you create more accurate queries and makes it easier to fix queries that return incorrect results.
This article is part of a series on SQL for Access. It describes the basics of using SQL to fetch data and provides examples of SQL syntax.
SQL is a programming language for working with sets of facts and relationships between them. Relational database management programs such as Microsoft Office Access use SQL to manipulate data. Unlike many programming languages, SQL is readable and understandable even for beginners. Like many programming languages, SQL is an international standard recognized by standards committees such as ISO and ANSI.
Datasets are described in SQL to help answer questions. Correct syntax must be used when using SQL. Syntax is a set of rules for correctly combining elements of a language. SQL syntax is based on English syntax and shares many elements with Visual Basic for Applications (VBA) syntax.
For example, a simple SQL statement that retrieves a list of last names of contacts named Mary might look like this:
SELECT Last_Name
FROM Contacts
WHERE First_Name = "Mary";
Note: The SQL language is used not only to perform operations on data, but also to create and modify the structure of database objects, such as tables. The part of SQL that is used to create and modify database objects is called the DDL. DDL is not covered in this article. For more information, see the article Create and Modify Tables or Indexes by Using a Data Definition Query.
The SELECT statement is used to describe a dataset in SQL. It contains a complete description of the dataset to be retrieved from the database, including the following:
tables that contain data;
links between data from different sources;
fields or calculations on the basis of which the data is selected;
selection conditions that must be met by the data included in the query result;
the need and method of sorting.
An SQL statement is made up of several parts called clauses. Each clause in a SQL statement has a different purpose. Some suggestions are required. The following table lists the SQL statements that are used most often.
SQL clause | Description | Mandatory |
|---|---|---|
|
Defines the fields that contain the data you want. |
||
|
Defines tables that contain the fields specified in the SELECT clause. |
||
|
Defines the criteria for selecting fields that must be met by all records included in the results. |
||
|
Determines the sort order of the results. |
||
|
In an SQL statement that contains aggregate functions, identifies the fields for which the SELECT clause does not calculate a summary value. |
Only if there are such fields |
|
|
In an SQL statement that contains aggregate functions, defines the conditions that apply to fields for which the SELECT clause calculates a summary value. |
Each SQL statement is composed of terms that can be compared to parts of speech. The following table lists the types of SQL terms.
SQL term | Comparable part of speech | Definition | Example |
|---|---|---|---|
|
identifier |
noun |
The name used to identify the database object, such as the name of a field. |
Customers. [Phone Number] |
|
operator |
verb or adverb |
A keyword that represents or modifies an action. |
|
|
constant |
noun |
A value that does not change, such as a number or NULL. |
|
|
expression |
adjective |
A combination of identifiers, operators, constants, and functions designed to compute a single value. |
> = Goods. [Price] |
General format of SQL statements:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Notes:
Access ignores line breaks in SQL statements. Regardless, it is recommended that you start each sentence on a new line so that the SQL statement is easy to read, both for the person who wrote it and for everyone else.
Each SELECT statement ends with a semicolon (;). The semicolon can appear either at the end of the last sentence or on a separate line at the end of the SQL statement.
The following example shows what an SQL statement might look like in Access for a simple select query.
1. SELECT clause
2. FROM clause
3. WHERE clause
Let's go through an example sentence by sentence to understand how the SQL syntax works.
SELECT, Company
This is a SELECT clause. It contains a statement (SELECT) followed by two identifiers ("[Email Address]" and "Company").
If the identifier contains spaces or special characters (for example, "Email Address"), it must be enclosed in square brackets.
In the SELECT clause, you do not need to specify the tables that contain the fields, and you cannot specify the selection criteria that must be met by the data included in the results.
In a SELECT statement, the SELECT clause always comes before the FROM clause.
FROM Contacts
This is a FROM clause. It contains an operator (FROM) followed by an identifier (Contacts).
Fields for selection are not specified in the FROM clause.
WHERE City = "Seattle"
This is a WHERE clause. It contains the (WHERE) operator followed by the expression (City = "Rostov").
There are many things you can do with SELECT, FROM, and WHERE clauses. For more information on using these suggestions, see the following articles:
As with Microsoft Excel, Access can sort query results in a table. By using the ORDER BY clause, you can also specify how the results are sorted when the query is run. If an ORDER BY clause is used, it must appear at the end of the SQL statement.
The ORDER BY clause contains a list of fields to be sorted in the same order in which the sort will be applied.
For example, suppose the results first need to be sorted by the Company field in descending order, and then, if there are records with the same Company field value, they must be sorted by the Email Address field in ascending order. The ORDER BY clause would look like this:
ORDER BY Company DESC,
Note: By default, Access sorts the values in ascending order (A to Z, smallest to largest). To sort the values in descending order instead, you must specify the DESC keyword.
For more information about the ORDER BY clause, see the article ORDER BY Clause.
Sometimes you need to work with aggregate data, such as total monthly sales or the most expensive items in stock. To do this, an aggregate function is applied to the field in the SELECT clause. For example, if the query is to retrieve the number of email addresses for each company, the SELECT clause might look like this:
The ability to use a particular aggregate function depends on the type of data in the field and the desired expression. For more information on the available aggregate functions, see the article SQL aggregate functions.
When using aggregate functions, you usually need to create a GROUP BY clause. The GROUP BY clause specifies all fields that do not have an aggregate function applied. If aggregate functions are applied to all fields in a query, you do not need to create a GROUP BY clause.
The GROUP BY clause must immediately follow the WHERE or FROM clause if there is no WHERE clause. In the GROUP BY clause, the fields are specified in the same order as in the SELECT clause.
Let's continue with the previous example. If the SELECT clause applies the aggregate function only to the [Email Address] field, then the GROUP BY clause will look like this:
GROUP BY Company
For more information on the GROUP BY clause, see the article GROUP BY Clause.
If you need to specify conditions to limit the results, but the field to which you want to apply is used in an aggregated function, you cannot use the WHERE clause. Use the HAVING clause instead. The HAVING clause works the same as the WHERE clause, but is used for aggregated data.
For example, suppose you apply an AVG function (which calculates the average) to the first field in the SELECT clause:
SELECT COUNT (), Company
If you want to limit the query results based on the value of the COUNT function, you cannot apply a filter condition to that field in the WHERE clause. Instead, the condition should be placed in the HAVING clause. For example, if you want the query to return rows only if the company has multiple email addresses, you can use the following HAVING clause:
HAVING COUNT ()> 1
Note: A query can include both a WHERE clause and a HAVING clause, with the criteria for fields that are not used in aggregate functions specified in the WHERE clause, and conditions for fields that are used in aggregate functions in the HAVING clause.
For more information on the HAVING clause, see the article HAVING Clause.
The UNION operator is used to view all the data returned by multiple, similar select queries at the same time as a concatenated set.
The UNION operator allows you to combine two SELECT statements into one. The SELECT statements to be merged must have the same number and order of output fields with the same or compatible data types. When you run a query, data from each set of matching fields is combined into a single output field, so the query output has the same number of fields as each SELECT statement individually.
Note: In union queries, numeric and text data types are compatible.
Using the UNION operator, you can specify whether duplicate rows, if any, should be included in the query results. To do this, use the ALL keyword.
A query to combine two SELECT statements has the following basic syntax:
SELECT field_1
FROM table_1
UNION
SELECT field_a
FROM table_a
;
For example, suppose you have two tables called "Products" and "Services". Both tables contain fields with the name of the product or service, price and warranty information, as well as a field that indicates the exclusivity of the product or service offered. Although there are different types of guarantees in the Products and Services tables, the basic information is the same (is there a quality guarantee for individual products or services). You can use the following join query to combine four fields from two tables:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
For more information on combining SELECT statements using the UNION operator, see the article
Basic SQL Commands Every Programmer Should Know
SQL, or Structured Query Language, is used to manipulate data in a relational database system (RDBMS). This article will talk about commonly used SQL commands that every programmer should be familiar with. This material is ideal for those looking to brush up on their SQL knowledge before a job interview. To do this, analyze the examples given in the article and remember what you went through in pairs through the databases.
Note that some database systems require a semicolon at the end of each statement. The semicolon is a standard pointer to the end of every statement in SQL. The examples use MySQL, so a semicolon is required.
Create a database to demonstrate how teams work. To work, you need to download two files: DLL.sql and InsertStatements.sql. After that, open a terminal and enter the MySQL console with the following command (this article assumes that MySQL is already installed on the system):
Mysql -u root -p
Then enter the password.
Run the following command. Let's call the database "university":
CREATE DATABASE university; USE university; SOURCE You may need to create constraints for specific columns in the table. When creating a table, you can set the following restrictions: More than one primary key can be specified. In this case, you get a composite primary key. Create table "instructor": CREATE TABLE instructor (ID CHAR (5), name VARCHAR (20) NOT NULL, dept_name VARCHAR (20), salary NUMERIC (8,2), PRIMARY KEY (ID), FOREIGN KEY (dept_name) REFERENCES department (dept_name)); You can view various information (value type, key or not) about the table columns with the following command: DESCRIBE When adding data to each column of the table, you do not need to specify the column names. INSERT INTO SELECT is used to retrieve data from a specific table: SELECT The following command can display all data from the table: SELECT * FROM Table columns can contain duplicate data. Use SELECT DISTINCT to get only non-duplicate data. SELECT DISTINCT You can use the WHERE keyword in SELECT to specify conditions in a query: SELECT The following conditions can be specified in the request: Try the following commands. Pay attention to the conditions specified in the WHERE: SELECT * FROM course WHERE dept_name = 'Comp. Sci. '; SELECT * FROM course WHERE credits> 3; SELECT * FROM course WHERE dept_name = "Comp. Sci." AND credits> 3; The GROUP BY clause is often used with aggregate functions such as COUNT, MAX, MIN, SUM, and AVG to group output values. SELECT Let's display the number of courses for each faculty: SELECT COUNT (course_id), dept_name FROM course GROUP BY dept_name; The HAVING keyword was added to SQL because WHERE cannot be used with aggregate functions. SELECT Let's list the faculties with more than one course: SELECT COUNT (course_id), dept_name FROM course GROUP BY dept_name HAVING COUNT (course_id)> 1; ORDER BY is used to sort query results in descending or ascending order. ORDER BY will sort in ascending order if no ASC or DESC sorting method is specified. SELECT Let's display a list of courses in ascending and descending order of the number of credits: SELECT * FROM course ORDER BY credits; SELECT * FROM course ORDER BY credits DESC; BETWEEN is used to select data values from a specified range. Numeric and text values as well as dates can be used. SELECT Here's a list of instructors whose salary is more than 50,000 but less than 100,000: SELECT * FROM instructor WHERE salary BETWEEN 50000 AND 100000; The LIKE operator is used in WHERE to specify a search pattern for a similar value. There are two free operators that are used in LIKE: Let's display a list of courses, the name of which contains "to", and a list of courses, the name of which begins with "CS-": SELECT * FROM course WHERE title LIKE '% to%'; SELECT * FROM course WHERE course_id LIKE "CS -___"; Using IN, you can specify multiple values for the WHERE clause: SELECT Let's display a list of students from Comp. Sci. Physics and Elec. Eng .: SELECT * FROM student WHERE dept_name IN ('Comp. Sci.', 'Physics', 'Elec. Eng.'); JOIN is used to link two or more tables using common attributes within them. The image below shows the different ways to combine in SQL. Note the difference between a left outer join and a right outer join: SELECT We will display a list of all courses and the corresponding information about the faculties: SELECT * FROM course JOIN department ON course.dept_name = department.dept_name; Let's list all the required courses and details about them: SELECT prereq.course_id, title, dept_name, credits, prereq_id FROM prereq LEFT OUTER JOIN course ON prereq.course_id = course.course_id; Let's display a list of all courses, regardless of whether they are required or not: SELECT course.course_id, title, dept_name, credits, prereq_id FROM prereq RIGHT OUTER JOIN course ON prereq.course_id = course.course_id; View is a virtual SQL table created by executing an expression. It contains rows and columns and is very similar to a regular SQL table. View always shows the latest information from the database. Let's create a view consisting of courses with 3 credits: These functions are used to obtain an aggregate result related to the data in question. The following are commonly used aggregate functions: Nested subqueries are SQL queries that include SELECT, FROM, and WHERE clauses nested within another query. Let's find the courses that were taught in autumn 2009 and spring 2010: SELECT DISTINCT course_id FROM section WHERE semester = 'Fall' AND year = 2009 AND course_id IN (SELECT course_id FROM section WHERE semester = 'Spring' AND year = 2010); If you are like me, then you will agree: SQL is one of those things that at first glance seem easy (it reads as if in English!), But for some reason you have to google every simple query to find the correct syntax. And then joins, aggregations, subqueries begin, and it turns out completely nonsense. It seems like this: Bue! This will scare off any newbie, or even a mid-level developer, if this is his first time seeing SQL. But it is not all that bad. It's easy to remember what is intuitive, and with the help of this tutorial, I hope to lower the threshold for SQL entry for newbies, and to offer experienced ones a fresh look at SQL. Although the SQL syntax is almost the same in different databases, this article uses PostgreSQL for queries. Some examples will work in MySQL and other databases. There are many keywords in SQL, but SELECT, FROM and WHERE appear in almost every query. A little later, you will realize that these three words represent the most fundamental aspects of building database queries, and other, more complex queries are just add-ons on top of them. Let's take a look at the database we'll be using as an example in this article: We have a book library and people. There is also a special table for accounting of issued books. Let's start with a simple query: we need names and identifiers(id) of all books written by the author "Dan Brown" The request will be like this: And the result is like this: Pretty simple. Let's take a look at the request to understand what's going on. This may seem obvious now, but FROM will be very important later when we get to joins and subqueries. FROM points to the table to query against. This can be an existing table (as in the example above), or a table created on the fly via joins or subqueries. WHERE just behaves like a filter strings that we want to output. In our case, we want to see only those lines where the value in the author column is “Dan Brown”. Now that we have all the columns we need from the table we need, we need to decide how to display this data. In our case, only the titles and identifiers of the books are needed, so this is what we and choose using SELECT. At the same time, you can rename the column using AS. The entire query can be visualized with a simple diagram: Now we want to see the titles (not necessarily unique) of all of Dan Brown's books that were pulled from the library, and when these books need to be returned: Result: For the most part, the request is similar to the previous one. with the exception of FROM sections. It means that we request data from another table... We are not accessing either the books table or the borrowings table. Instead, we refer to new table which was created by joining the two tables. borrowings JOIN books ON borrowings.bookid = books.bookid is a new table that was formed by combining all records from the "books" and "borrowings" tables in which the bookid values are the same. The result of such a merge will be: And then we query this table in the same way as in the example above. This means that when joining tables, you only need to worry about how to make that join. And then the request becomes as clear as in the case of the “simple request” from point 3. Let's try a slightly more complex two-table join. Now we want to get the first and last names of people who have taken from the library of the author's book "Dan Brown". This time, let's go from bottom to top: Step Step 1- where do we get the data from? To get the result we want, we need to join the "member" and "books" tables with the "borrowings" table. The JOIN section will look like this: The connection result can be seen at the link. Step 2- what data are we showing? We are only interested in the data where the author of the book is “Dan Brown” Step 3- how do we display the data? Now that the data has been received, you just need to display the name and surname of those who took the books: Super! It remains only to combine the three components and make the request we need: Which will give us: Fine! But the names are repeated (they are not unique). We will fix this soon. Roughly speaking, aggregations are needed to convert multiple rows into one... At the same time, during aggregation, different logic is used for different columns. Let's continue with our example where duplicate names appear. It can be seen that Ellen Horton borrowed more than one book, but this is not the best way to show this information. Another request can be made: Which will give us the desired result: Almost all aggregations come with a GROUP BY clause. This thing turns a table that could be retrieved by a query into groups of tables. Each group corresponds to a unique value (or group of values) for the column we specified in the GROUP BY. In our example, we are converting the result from the previous exercise into a row group. We also aggregate with count, which converts multiple rows to an integer value (in our case, this is the number of rows). Then this value is assigned to each group. Each row in the result is the result of the aggregation of each group. You can come to the logical conclusion that all fields in the result should either be specified in the GROUP BY, or aggregation should be performed on them. Because all other fields can differ from each other in different rows, and if you select them with SELECT, it is not clear which of the possible values should be taken. In the example above, the count function processed all the lines (since we were counting the number of lines). Other functions like sum or max only process the specified strings. For example, if we want to find out the number of books written by each author, then we need a query like this: Result: Here, the sum function only processes the stock column and calculates the sum of all values in each group. Subqueries are regular SQL queries embedded in larger queries. They are divided into three types according to the type of the returned result. There are queries that return multiple columns. A good example is the query from the last aggregation exercise. As a subquery, it will simply return another table against which new queries can be made. Continuing the previous exercise, if we want to find out the number of books written by the author of "Robin Sharma", then one of the possible ways is to use subqueries: Result: Can be written as: ["Robin Sharma", "Dan Brown"] 2. Now let's use this result in a new query: Result: This is the same as: There are queries that result in just one row and one column. They can be treated as constant values and can be used wherever values are used, such as in comparison operators. They can also be used as two-dimensional tables or single-element arrays. Let's, for example, get information about all the books that are in excess of the current average in the library. The average can be obtained this way: Which gives us: Most database writes are fairly straightforward compared to more complex reads. The syntax for an UPDATE query is semantically the same as for a read query. The only difference is that instead of selecting the SELECT columns, we set the SET values. If all of Dan Brown's books are lost, then you need to reset the quantity value. The request for this will be like this: WHERE does the same as before: selects rows. Instead of the SELECT that was used when reading, we now use SET. However, now you need to specify not only the name of the column, but also the new value for this column in the selected rows. A DELETE query is just a SELECT or UPDATE query with no column names. Seriously. As with SELECT and UPDATE, the WHERE clause remains the same: it selects the rows to be deleted. The delete operation destroys the entire row, so it doesn't make sense to specify separate columns. So, if we decide not to reset the number of Dan Brown's books, but to delete all records altogether, then we can make the following request: Perhaps the only thing that differs from other types of queries is INSERT. The format is: Where a, b, c are the names of the columns, and x, y and z are the values to be inserted into those columns, in the same order. That's basically it. Let's take a look at a specific example. Here is an INSERT query that populates the entire "books" table: We have come to the end, I propose a small test. Take a look at that request at the very beginning of the article. Can you figure it out? Try to break it down into SELECT, FROM, WHERE, GROUP BY clauses, and look at the individual components of the subqueries. Here it is in a more readable form: This query returns a list of people who have checked out a book from the library that has an above average total. Result: I hope you managed to figure it out without any problems. But if not, I would appreciate your comments and feedback so that I can improve this post.Database Commands
1. View available databases
SHOW DATABASES; 2. Creating a new database
CREATE DATABASE; 3. Choosing a database to use
USE 4. Importing SQL commands from the.sql file
SOURCE 5. Removing the database
DROP DATABASE Working with tables
6. Viewing tables available in the database
SHOW TABLES; 
7. Creating a new table
CREATE TABLE Integrity Constraints Using CREATE TABLE
Example
8. Table information

9. Adding data to the table
INSERT INTO 10. Updating table data
UPDATE 11. Removing all data from the table
DELETE FROM 12. Deleting a table
DROP TABLE Commands for making requests
13. SELECT

14. SELECT DISTINCT

15. WHERE
Example

16. GROUP BY
Example

17. HAVING
Example

18. ORDER BY
Example

19. BETWEEN
Example

20. LIKE
SELECT Example

21. IN
Example

22. JOIN

Example 1

Example 2

Example 3

23. View
Creation
CREATE VIEW Deleting
DROP VIEW Example

24. Aggregate functions
25. Nested subqueries
Example

Do you need “SELECT * WHERE a = b FROM c” or “SELECT WHERE a = b FROM c ON *”?
SELECT members.firstname || "" || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid = borrowings.memberid INNER JOIN books ON books.bookid = borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg (stock ) FROM books)) GROUP BY members.firstname, members.lastname; 1. Three magic words
2. Our base


3. Simple request
SELECT bookid AS "id", title FROM books WHERE author = "Dan Brown"; id
title
2
The lost symbol
4
Inferno
3.1 FROM - where we get the data from
3.2 WHERE - what data to show
3.3 SELECT - how to display data

4. Connections (joins)
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid = books.bookid WHERE books.author = "Dan Brown"; Title
Return Date
The lost symbol
2016-03-23 00:00:00
Inferno
2016-04-13 00:00:00
The lost symbol
2016-04-19 00:00:00

borrowings JOIN books ON borrowings.bookid = books.bookid JOIN members ON members.memberid = borrowings.memberid
WHERE books.author = "Dan Brown"
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid = books.bookid JOIN members ON members.memberid = borrowings.memberid WHERE books.author = "Dan Brown"; First Name
Last Name
Mike
Willis
Ellen
Horton
Ellen
Horton
5. Aggregation
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count (*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid = books.bookid JOIN members ON members.memberid = borrowings .memberid WHERE books.author = "Dan Brown" GROUP BY members.firstname, members.lastname; First Name
Last Name
Number of books borrowed
Mike
Willis
1
Ellen
Horton
2
SELECT author, sum (stock) FROM books GROUP BY author; author
sum
Robin sharma
4
Dan brown
6
John green
3
Amish tripathi
2
6. Subqueries

6.1 Two-dimensional table
SELECT * FROM (SELECT author, sum (stock) FROM books GROUP BY author) AS results WHERE author = "Robin Sharma";
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum (stock) FROM books GROUP BY author) AS results WHERE sum> 3); title
bookid
The lost symbol
2
Who Will Cry When You Die?
3
Inferno
4
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown"); 6.3 Individual values
select avg (stock) from books; 7. Write operations
7.1 Update
UPDATE books SET stock = 0 WHERE author = "Dan Brown"; 7.2 Delete
DELETE FROM books WHERE author = "Dan Brown"; 7.3 Insert
INSERT INTO x (a, b, c) VALUES (x, y, z);
INSERT INTO books (bookid, title, author, published, stock) VALUES (1, "Scion of Ikshvaku", "Amish Tripathi", "06-22-2015", 2), (2, "The Lost Symbol", " Dan Brown "," 07-22-2010 ", 3), (3," Who Will Cry When You Die? "," Robin Sharma "," 06-15-2006 ", 4), (4," Inferno " , "Dan Brown", "05-05-2014", 3), (5, "The Fault in our Stars", "John Green", "01-03-2015", 3); 8. Verification
SELECT members.firstname || "" || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid = borrowings.memberid INNER JOIN books ON books.bookid = borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg (stock ) FROM books)) GROUP BY members.firstname, members.lastname; Full Name
Lida tyler










