Lekce se bude zabývat dotazovacím jazykem sql: základy syntaxe jazyka sql, práce v phpMyAdmin a služba pro online kontrolu sql dotazů
Databáze- centralizované úložiště dat zajišťující úložiště, přístup, primární zpracování a získávání informací.
Databáze se dělí na:
SQL (Structured Query Language)- je strukturovaný dotazovací jazyk (přeložen z angličtiny). Jazyk je zaměřen na práci s relačními (tabulkovými) databázemi. Jazyk je jednoduchý a ve skutečnosti se skládá z příkazů (interpretovaných), pomocí kterých můžete pracovat s velkým množstvím dat (databází), mazat, přidávat, měnit v nich informace a provádět pohodlné vyhledávání.
Pro práci s kódem SQL potřebujete systém správy databází (DBMS), který poskytuje funkce pro práci s databázemi.
Systém pro správu databází(DBMS) - sada jazykových a softwarových nástrojů navržených pro vytváření, údržbu a sdílení databáze mnoha uživateli.
Obvykle se používá pro školení Microsoft Access DBMS, ale ve webové sféře použijeme běžnější systém -. Pro pohodlí bude používat webové rozhraní nebo online službu k vytváření sql dotazů, jejichž princip práce je popsán níže.
Důležité: Při práci s relačními nebo tabulkovými databázemi budou volány řádky tabulky evidence a sloupce jsou okraje.
Každý sloupec musí mít svůj vlastní datový typ, tj. by měl být navržen tak, aby zadával data konkrétního typu. jsou popsány v jedné z lekcí tohoto kurzu.
Jazyk SQL se skládá z následujících komponent:
1.
Jazyk pro manipulaci s daty se skládá ze 4 hlavních příkazů:
Jazyk definice dat slouží k vytváření a úpravám struktury databáze a jejích součástí - tabulek, indexů, pohledů (virtuálních tabulek), jakož i spouštěčů a uložených procedur.
Budeme zvažovat jen několik z nich základní jazykové příkazy... Oni jsou:
Data Management Language se používá ke správě přístupových práv k datům a provádění procedur ve víceuživatelském prostředí.
Nejprve musíte dokončit první dva body od.
Pak:

Online služba SQL dotazů je možná pomocí služby.
Nejsnadnější způsob organizace práce se skládá z následujících kroků:

Další příklad: 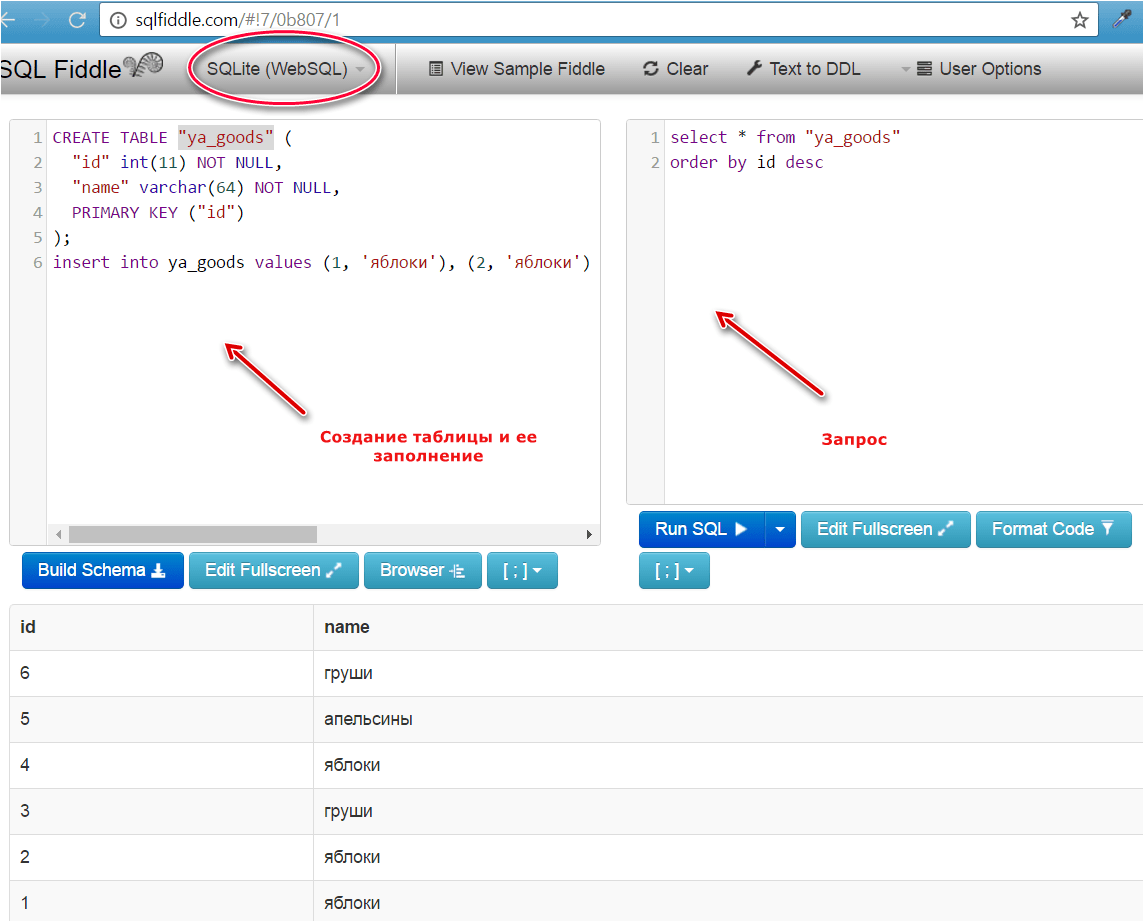
Nyní budeme zvažovat některé body podrobněji.
Vytváření tabulek:
Příklad: vytvořit tři tabulky najednou (učitelé, lekce a kurzy); přidat více hodnot do každé tabulky.
* pro ty, kteří neznají syntaxi - stačí zkopírovat celý kód a vložit jej do levého okna služby
* lekce o vytváření tabulek v SQL
| / * učitelé * / VYTVOŘIT TABULKU `teacher` (` id` INT (11) NOT NULL, `name` VARCHAR (25) NOT NULL,` code` INT (11), `zarplata` INT (11),` premia` INT (11), PRIMARY KEY (`id`)); VLOŽTE DO HODNOT učitelů (1, „Ivanov“, 1, 10 000, 500), (2, „Petrov“, 1, 15 000, 1 000), (3, „Sidorov“, 1, 14 000, 800), (4, “ Bobrová “, 1, 11 000, 800); / * lekce * / VYTVOŘIT TABULKU `lekce` (` id` INT (11) NOT NULL, `tid` INT (11),` course` VARCHAR (25), `date` VARCHAR (25), PRIMARY KEY (` id `)); VLOŽTE HODNOTY lekcí (1, 1, „php“, „2015-05-04“), (2, 1, „xml“, „2016-13-12“); / * kurzy * / VYTVOŘIT TABULKU `kurzy` (` id` INT (11) NOT NULL, `tid` INT (11),` title` VARCHAR (25), `length` INT (11), PRIMARY KEY (` id `)); VLOŽTE DO HODNOT kurzů (1, 1, "php", 54), (2, 1, "xml", 72), (3, 2, "sql", 25); |
/ * učitelé * / VYTVOŘIT TABULKU `teacher` (` id` int (11) NOT NULL, `name` varchar (25) NOT NULL,` code` int (11), `zarplata` int (11),` premia` int (11), PRIMARY KEY (`id`)); vložte do učitelů hodnoty (1, „Ivanov“, 1 10000 500), (2, „Petrov“, 1 15 000 1 000), (3, „Sidorov“, 1 14 000 800), (4 , „Bobrov“, 1 11 000 800); / * lekce * / VYTVOŘIT TABULKU `lekce` (` id` int (11) NOT NULL, `tid` int (11),` course` varchar (25), `date` varchar (25), PRIMARY KEY (` id `)); vložte do lekcí hodnoty (1,1, "php", "2015-05-04"), (2,1, "xml", "2016-13-12"); / * kurzy * / VYTVOŘIT TABULKU `kurzy` (` id` int (11) NOT NULL, `tid` int (11),` title` varchar (25), `length` int (11), PRIMARY KEY (` id `)); vložte do kurzů hodnoty (1,1, "php", 54), (2,1, "xml", 72), (3,2, "sql", 25);
V důsledku toho získáme tabulky s daty: 
Odeslání požadavku:
Chcete -li otestovat provozuschopnost, přidejte kód požadavku do pravého okna.
Příklad: pomocí dotazu vyberte všechna data z tabulky učitelů pro učitele s příjmením Ivanov
V dalších lekcích SQL bude použito stejné schéma, takže stačí schéma zkopírovat a vložit do levého okna služby.
Pro online vizualizaci schématu databáze můžete využít službu https://dbdesigner.net/:

Programování zapnuto T- SQL
Syntaxe a konvence T-SQL
Pravidla pro tvorbu identifikátorů
Všechny objekty na serveru SQL Server mají názvy (identifikátory). Příklady objektů jsou tabulky, pohledy, uložené procedury atd. Identifikátory mohou mít až 128 znaků, například písmena, _ @ $ # symboly a čísla.
První znak musí být vždy abecední. Pro proměnné a dočasné tabulky se používají speciální schémata pojmenování. Název objektu nesmí obsahovat mezery a nemůže se shodovat s klíčovým slovem vyhrazeným pro SQL Server, bez ohledu na použitý případ. Neplatné znaky v názvech objektů můžete použít tak, že identifikátory uzavřete do hranatých závorek.
Dokončení pokynů
ANSI SQL vyžaduje na konci každého příkazu středník. Při programování v T-SQL je však středník volitelný.
Komentáře (1)
T-SQL přijímá dva styly komentářů: ANCI a C. První začíná dvěma pomlčkami a končí na konci řádku:
Toto je jednořádkový komentář ve stylu ANSI
Komentáře ve stylu ANSI lze také vložit na konec řádku příkazu:
VYBRAT název města - načtené sloupce
Z MĚSTA - zdrojová tabulka
KDE IdCity = 1; - liniové omezení
Editor SQL může použít a odebrat komentáře na všech vybraných řádcích. Chcete -li to provést, vyberte v nabídce příslušné příkazy Upravit nebo na panelu nástrojů.
Komentáře ve stylu C začínají lomítkem a hvězdičkou (/ *) a končí stejnými znaky v opačném pořadí. Tento typ komentáře se nejlépe používá k komentování bloků řádků, jako jsou záhlaví nebo velké testovací dotazy.
víceřádkový
komentář
Jednou z hlavních výhod komentářů ve stylu C je, že v nich můžete spouštět víceřádkové dotazy, aniž byste museli odkomentovat.
Balíčky T-SQL
Dotaz je jeden příkaz T-SQL a dávka je jejich kolekce. Celá sekvence paketových instrukcí je odeslána na server z klientských aplikací jako jedna integrální jednotka.
SQL Server považuje celý balíček za jednotku práce. Přítomnost chyby alespoň v jedné instrukci povede k nemožnosti provedení celého balíčku. Analýza zároveň nekontroluje názvy objektů a schémat, protože samotné schéma se může během provádění příkazu změnit.
Soubor skriptu SQL a okno analyzátoru dotazů mohou obsahovat více balíčků. V tomto případě všechny balíčky sdílejí klíčová slova terminátoru. Ve výchozím nastavení je toto klíčové slovo GO a musí být jediné na řádku. Všechny ostatní znaky (dokonce i komentáře) negují oddělovač paketů.
Ladění T-SQL
Když editor SQL narazí na chybu, zobrazí povahu chyby a číslo řádku v dávce. Poklepáním na chybu můžete okamžitě přeskočit na odpovídající řádek.
Nástroj SQL Server 2005 Management Studio neobsahuje ladicí program T-SQL-je součástí balíčku Visual Studio.
SQL Server nabízí několik příkazů, které vám pomohou s laděním balíčků. Zejména příkaz PRINT odešle zprávu bez generování datové sady výsledků. Příkaz PRINT lze použít ke sledování postupu balíku. S analyzátorem dotazů v mřížkovém režimu spusťte následující dávku:
VYBRAT název města
Z MĚSTA
KDE IdCity = 1;
TISK "Kontrolní bod";
Výsledná datová sada se zobrazí v mřížce a bude jeden řádek. Na kartě Zprávy se současně zobrazí následující výsledek:
(zpracované řádky: 1)
Kontrolní bod
Proměnné
Proměnné T-SQL se vytvářejí pomocí příkazu DECLARE, který má následující syntaxi:
DECLARE @ Variable_Name Data_type [,
@ Název_proměnné Data_type, ...]
Všechny názvy místních proměnných musí začínat znakem @. Chcete -li například deklarovat místní proměnnou UStr, která ukládá až 16 znaků Unicode, můžete použít následující příkaz:
DECLARE @UStr varchar (16)
Datové typy použité pro proměnné jsou přesně stejné jako v tabulkách. V jednom příkazu DECLARE může být uvedeno několik proměnných, oddělených čárkami. Následující příklad konkrétně vytvoří dvě celočíselné proměnné aab:
PROHLÁSIT
@int,
@b int
Proměnné jsou pro aktuální balíček pouze v rozsahu (tj. Jejich životnosti). Nově vytvořené proměnné standardně obsahují nulové hodnoty NULL a je nutné je před zahrnutím do výrazů inicializovat.
Nastavení hodnot proměnných
Aktuálně SQL poskytuje dva způsoby nastavení hodnoty proměnné - k tomuto účelu můžete použít příkaz SELECT nebo SET. Pokud jde o funkce, které vykonávají, tyto příkazy fungují téměř stejně, kromě toho, že příkaz SELECT načte původní přiřaditelnou hodnotu z tabulky uvedené v příkazu SELECT.
Příkaz SET se běžně používá k nastavení hodnot proměnných ve formě, která je běžnější v procedurálních jazycích. Mezi typické příklady použití tohoto operátoru patří následující:
SET @a = 1;
SET @b = @a * 1,5
Všimněte si, že všechny tyto operátory přímo provádějí přiřazení pomocí explicitních hodnot nebo jiných proměnných. Příkaz SET nelze použít k přiřazení hodnoty proměnné z dotazu; dotaz musí být proveden samostatně a teprve potom lze výsledný výsledek přiřadit pomocí příkazu SET. Například pokus o provedení takového příkazu generuje chybu:
DECLARE @c int
SET @c = COUNT (*) FROM City
VYBRAT @c
a následující prohlášení uspěje:
DECLARE @c int
SET @c = (SELECT COUNT (*) FROM City)
VYBRAT @c
Příkaz SELECT se obvykle používá k přiřazení hodnot proměnným, když zdroj informací, které mají být uloženy v proměnné, pochází z dotazu. Například akce prováděné ve výše uvedeném kódu jsou mnohem častěji implementovány pomocí příkazu SELECT:
DECLARE @c int
SELECT @c = COUNT (*) FROM City
VYBRAT @c
Všimněte si, že tento kód je trochu jasnější (zejména je stručnější, i když dělá totéž).
Je tedy možné formulovat následující obecně přijímanou dohodu o využívání obou operátorů.
Příkaz SET se používá, když má být provedeno jednoduché přiřazení proměnné, tj. pokud již byla přiřazená hodnota nastavena výslovně ve formě určité hodnoty nebo ve formě jiné proměnné.
Použití proměnných v dotazech SQL
Jednou z užitečných vlastností jazyka T-SQL je, že proměnné lze použít v dotazech, aniž by bylo nutné vytvářet složité dynamické řetězce, které vkládají proměnné do kódu programu. Dynamický SQL nadále existuje, ale jednu hodnotu lze snadněji změnit pomocí proměnné.
Kdekoli lze v dotazu použít výraz, lze také použít proměnnou. Následující příklad ukazuje použití proměnné v klauzuli WHERE:
DECLARE @IdProd int;
SET @IdProd = 1;
VYBRAT
Z PRODUKTU
KDE IdProd = @IdProd;
Globální systémové proměnné
SQL Server má více než třicet globálních proměnných bez parametrů, které jsou definovány a udržovány systémem. Všechny globální proměnné mají předponu se dvěma symboly @. Hodnotu kterékoli z nich můžete načíst jednoduchým dotazem SELECT, jako v následujícím příkladu:
VYBERTE @@ PŘIPOJENÍ
K načtení počtu připojení k serveru SQL Server od spuštění programu používá globální proměnnou @@ CONNECTIONS.
Některé z nejčastěji používaných systémových proměnných jsou:
! Všimněte si toho, že od SQL Server 2000 jsou globální proměnné označovány jako funkce. Název globální zmatení uživatelé, což naznačuje, že rozsah takových proměnných je širší než rozsah místních proměnných. Možnost ukládat informace bez ohledu na to, zda jsou v balíčku obsaženy, či nikoli, byla často mylně přisuzována globálním proměnným, které samozřejmě neodpovídaly realitě.
Řízení toku příkazů. Softwarové konstrukce
Jazyk T-SQL poskytuje většinu klasických procedurálních nástrojů pro řízení toku provádění programu, vč. podmíněná konstrukce a smyčky.
OperátorLI. ... ... JINÝ
IF prohlášení. ... .ELSE funguje v T-SQL téměř stejně jako v jakémkoli jiném programovacím jazyce. Obecná syntaxe pro tento operátor je následující:
IF Booleovský výraz
Příkaz SQL I ZAČÍNÁ Blok příkazů SQL KONEC
Příkaz SQL | ZAČÍT SQL blok příkazů END]
Jako logický výraz lze zadat téměř jakýkoli výraz, jehož výsledek je vyhodnocen jako logická hodnota.
Je třeba mít na paměti, že pouze příkaz, který bezprostředně následuje po příkazu IF (nejblíže k němu), je považován za provedený podle podmínky. Namísto jednoho operátoru můžete zajistit provedení několika operátorů podle podmínky, jejich spojením do bloku kódu pomocí konstrukce BEGIN ... END.
V níže uvedeném příkladu není splněna podmínka IF, která brání spuštění následujícího příkazu.
IF 1 = 0
TISK "První řádek"
TISK "Druhý řádek"
Volitelný příkaz ELSE vám umožňuje zadat příkaz, který se má provést, pokud není splněna podmínka IF. Stejně jako IF, příkaz ELSE ovládá pouze bezprostředně následující příkaz nebo blok kódu mezi BEGIN ... END.
Ačkoli příkaz IF vypadá omezeně, jeho klauzule podmínky může obsahovat výkonné funkce, jako je klauzule WHERE. Zejména se jedná o výrazy IF EXISTS ().
Výraz IF EXISTS () používá jako podmínku existenci libovolného řádku vráceného příkazem SELECT. Protože jsou prohledávány všechny řádky, lze seznam sloupců v příkazu SELECT nahradit hvězdičkou. Tato metoda je rychlejší než kontrola podmínky @@ ROWCOUNT> 0, protože není nutné počítat celkový počet řádků. Jakmile alespoň jeden řádek splňuje podmínku IF EXISTS (), může dotaz pokračovat v provádění.
Následující příklad používá výraz IF EXISTS ke kontrole, zda má zákaznický kód 1 nějaké objednávky před jeho odstraněním z databáze. Pokud existují informace o alespoň jedné objednávce pro tohoto klienta, odstranění se neprovede.
POKUD EXISTUJE (VYBERTE * ODKUD IdCust = 1)
TISK „Klienta nelze odstranit, protože v databázi jsou k němu přidruženy záznamy“
JINÝ
KDE IdCust = 1
TISK "Odstranění bylo úspěšně dokončeno"
OperátořiZATÍMCO, PŘERUŠENÍ aPOKRAČOVAT
Klauzule WHILE v SQL funguje téměř stejně jako v jiných jazycích, se kterými musí programátor obvykle pracovat. V tomto prohlášení je ve skutečnosti kontrolována určitá podmínka před začátkem každého průchodu smyčkou. Pokud před dalším průchodem smyčky výsledkem kontroly podmínky je PRAVDA, smyčka se smyčkou projde, jinak je příkaz ukončen.
Příkaz WHILE má následující syntaxi:
PŘI Booleovském výrazu
Příkaz SQL I.
Blok příkazů SQL
Samozřejmě pomocí příkazu WHILE můžete zajistit, aby byl ve smyčce proveden pouze jeden příkaz (podobně jako se obvykle používá příkaz IF), ale v praxi WHILE konstruuje, za kterými nenásleduje blok BEGIN. ... .END vyhovující úplnému formátu operátora je vzácné.
Příkaz BREAK vám umožňuje okamžitě opustit smyčku, aniž byste čekali, až bude provedeno předání na konec smyčky a znovu bude zkontrolován podmíněný výraz.
Příkaz CONTINUE vám umožňuje přerušit jednu iteraci smyčky. Můžete stručně popsat akci příkazu CONTINUE tak, aby přeskočil na začátek cyklu WHILE. Jakmile je ve smyčce nalezen operátor CONTINUE, bez ohledu na to, kde se nachází, smyčka přejde na začátek smyčky a podmíněný výraz se znovu vyhodnotí (a pokud hodnota tohoto výrazu již není PRAVDA, smyčka je ukončena).
Následující krátký skript ukazuje použití klauzule WHILE k vytvoření smyčky:
DECLARE @Temp int;
SET @Temp = 0;
KDYŽ @teplota< 3
ZAČÍT
TISK @teplota;
SET @Temp = @Temp + 1;
Zde se ve smyčce celočíselná proměnná @Teplota zvyšuje o 0 až 3 a při každé iteraci se zobrazuje její hodnota.
OperátorVRÁTIT SE
Příkaz RETURN se používá k zastavení provádění balíčku, a tedy uložené procedury a spouštěče (zahrnuto v další laboratoři).
Jazyk SQL se používá k načítání dat z databáze. SQL je programovací jazyk, který se velmi podobá angličtině, ale je určen pro programy pro správu databází. SQL se používá v každém dotazu v Accessu.
Pochopení fungování SQL vám pomůže vytvořit přesnější dotazy a usnadní opravu dotazů, které vracejí nesprávné výsledky.
Tento článek je součástí řady článků o SQL for Access. Popisuje základy používání SQL k načítání dat a poskytuje příklady syntaxe SQL.
SQL je programovací jazyk pro práci se sadami faktů a vztahů mezi nimi. Programy pro správu relační databáze, jako je Microsoft Office Access, používají k manipulaci s daty SQL. Na rozdíl od mnoha programovacích jazyků je SQL čitelný a srozumitelný i pro začátečníky. Stejně jako mnoho programovacích jazyků je SQL mezinárodní standard uznávaný normalizačními výbory, jako jsou ISO a ANSI.
Datové sady jsou popsány v SQL, aby pomohly odpovědět na otázky. Při používání SQL je nutné použít správnou syntaxi. Syntaxe je sada pravidel pro správné kombinování prvků jazyka. Syntaxe SQL je založena na anglické syntaxi a sdílí mnoho prvků se syntaxí jazyka Visual Basic for Applications (VBA).
Jednoduchý příkaz SQL, který načte seznam příjmení kontaktů s názvem Mary, může vypadat například takto:
VYBERTE příjmení
Z kontaktů
WHERE First_Name = "Mary";
Poznámka: Jazyk SQL slouží nejen k provádění operací s daty, ale také k vytváření a úpravám struktury databázových objektů, například tabulek. Část SQL, která se používá k vytváření a úpravám databázových objektů, se nazývá DDL. Tento článek se nezabývá DDL. Další informace najdete v článku Vytváření a úpravy tabulek nebo indexů pomocí dotazu na definici dat.
Příkaz SELECT se používá k popisu datové sady v SQL. Obsahuje úplný popis datové sady, která má být načtena z databáze, včetně následujících:
tabulky, které obsahují data;
vazby mezi údaji z různých zdrojů;
pole nebo výpočty, na jejichž základě jsou data vybírána;
podmínky výběru, které musí splňovat data obsažená ve výsledku dotazu;
potřeba a způsob třídění.
Příkaz SQL se skládá z několika částí nazývaných klauzule. Každá klauzule v příkazu SQL má jiný účel. Jsou vyžadována některá doporučení. Následující tabulka uvádí nejčastěji používané klauzule SQL.
SQL klauzule | Popis | Povinné |
|---|---|---|
|
Definuje pole, která obsahují požadovaná data. |
||
|
Definuje tabulky, které obsahují pole uvedená v klauzuli SELECT. |
||
|
Určuje kritéria pro výběr polí, která musí splňovat všechny záznamy zahrnuté ve výsledcích. |
||
|
Určuje pořadí řazení výsledků. |
||
|
V příkazu SQL, který obsahuje agregační funkce, identifikuje pole, pro která klauzule SELECT nevypočítává souhrnnou hodnotu. |
Pouze pokud taková pole existují |
|
|
V příkazu SQL, který obsahuje agregační funkce, definuje podmínky, které platí pro pole, pro která klauzule SELECT vypočítá souhrnnou hodnotu. |
Každý příkaz SQL se skládá z výrazů, které lze porovnat s částmi řeči. Následující tabulka uvádí typy termínů SQL.
Termín SQL | Srovnatelná část řeči | Definice | Příklad |
|---|---|---|---|
|
identifikátor |
podstatné jméno |
Název používaný k identifikaci databázového objektu, například název pole. |
Zákazníci. [Telefonní číslo] |
|
operátor |
sloveso nebo příslovce |
Klíčové slovo, které představuje nebo upravuje akci. |
|
|
konstantní |
podstatné jméno |
Hodnota, která se nemění, například číslo nebo NULL. |
|
|
výraz |
přídavné jméno |
Kombinace identifikátorů, operátorů, konstant a funkcí navržených pro výpočet jedné hodnoty. |
> = Zboží. [Cena] |
Obecný formát příkazů SQL:
VYBRAT pole_1
Z tabulky_1
KDE kritérium_1
;
Poznámky:
Access ignoruje konce řádků v příkazech SQL. Bez ohledu na to se doporučuje začít každou větu na novém řádku, aby byl příkaz SQL snadno čitelný, a to jak pro osobu, která jej napsala, tak pro všechny ostatní.
Každý příkaz SELECT končí středníkem (;). Středník se může objevit buď na konci poslední věty, nebo na samostatném řádku na konci příkazu SQL.
Následující příklad ukazuje, jak by mohl vypadat příkaz SQL v Accessu pro jednoduchý výběrový dotaz.
1. Klauzule SELECT
2. FROM klauzule
3. Klauzule WHERE
Pojďme analyzovat příklad větu po větě, abychom pochopili, jak funguje syntaxe SQL.
SELECT, společnost
Toto je klauzule SELECT. Obsahuje příkaz (SELECT) následovaný dvěma identifikátory („[[e -mailová adresa]“ a „společnost“).
Pokud identifikátor obsahuje mezery nebo speciální znaky (například „e -mailová adresa“), musí být uzavřen v hranatých závorkách.
V klauzuli SELECT nemusíte zadávat tabulky, které pole obsahují, a nemůžete zadat kritéria výběru, která musí data obsažená ve výsledcích splňovat.
V příkazu SELECT klauzule SELECT vždy předchází klauzuli FROM.
Z kontaktů
Toto je klauzule FROM. Obsahuje operátor (FROM) následovaný identifikátorem (Kontakty).
Pole pro výběr nejsou v klauzuli FROM specifikována.
WHERE City = "Seattle"
Toto je klauzule WHERE. Obsahuje operátor (KDE) následovaný výrazem (Město = "Rostov").
Existuje mnoho věcí, které můžete dělat s klauzulemi SELECT, FROM a WHERE. Další informace o používání těchto návrhů naleznete v následujících článcích:
Stejně jako v Microsoft Excelu může Access třídit výsledky dotazů v tabulce. Pomocí klauzule ORDER BY můžete také určit způsob řazení výsledků při spuštění dotazu. Pokud je použita klauzule ORDER BY, musí se objevit na konci příkazu SQL.
Klauzule ORDER BY obsahuje seznam polí, která mají být tříděna, ve stejném pořadí, ve kterém bude řazení použito.
Předpokládejme například, že chcete nejprve seřadit výsledky podle pole Společnost v sestupném pořadí, a poté, pokud existují záznamy se stejnou hodnotou pole Společnost, seřadit je podle pole E -mailová adresa ve vzestupném pořadí. Klauzule ORDER BY bude vypadat takto:
OBJEDNÁVKA PODLE společnosti DESC,
Poznámka: Ve výchozím nastavení aplikace Access seřadí hodnoty ve vzestupném pořadí (od A do Z, od nejmenšího po největší). Chcete -li místo toho seřadit hodnoty v sestupném pořadí, musíte zadat klíčové slovo DESC.
Další informace o klauzuli ORDER BY naleznete v článku Klauzule ORDER BY.
Někdy je třeba pracovat s agregovanými daty, jako jsou celkové měsíční tržby nebo nejdražší položky na skladě. K tomu je na pole v klauzuli SELECT použita agregační funkce. Pokud má dotaz například načíst počet e -mailových adres pro každou společnost, klauzule SELECT může vypadat takto:
Možnost použít konkrétní agregační funkci závisí na typu dat v poli a požadovaném výrazu. Další informace o dostupných agregačních funkcích najdete v článku agregační funkce SQL.
Při používání agregačních funkcí obvykle potřebujete vytvořit klauzuli GROUP BY. Klauzule GROUP BY určuje všechna pole, u kterých není použita agregační funkce. Pokud jsou na všechna pole v dotazu použity agregační funkce, není nutné vytvářet klauzuli GROUP BY.
Klauzule GROUP BY musí okamžitě následovat klauzuli WHERE nebo FROM, pokud neexistuje klauzule WHERE. V klauzuli GROUP BY jsou pole zadána ve stejném pořadí jako v klauzuli SELECT.
Pokračujme předchozím příkladem. Pokud klauzule SELECT použije agregační funkci pouze na pole [E -mailová adresa], pak bude klauzule GROUP BY vypadat takto:
SKUPINA PODLE SPOLEČNOSTI
Další informace o klauzuli GROUP BY najdete v článku Klauzule GROUP BY.
Pokud potřebujete určit podmínky pro omezení výsledků, ale pole, na které chcete použít, je použito v agregované funkci, nemůžete použít klauzuli WHERE. Místo toho použijte klauzuli HAVING. Klauzule HAVING funguje stejně jako klauzule WHERE, ale používá se pro agregovaná data.
Předpokládejme například, že na první pole v klauzuli SELECT je použita funkce AVG (která vypočítává průměr):
SELECT COUNT (), Company
Pokud chcete omezit výsledky dotazu na základě hodnoty funkce COUNT, nemůžete na toto pole v klauzuli WHERE použít podmínku filtru. Místo toho by podmínka měla být umístěna v klauzuli HAVING. Pokud například chcete, aby dotaz vracel řádky pouze v případě, že společnost má více e -mailových adres, můžete použít následující klauzuli HAVING:
MÁME POČET ()> 1
Poznámka: Dotaz může obsahovat klauzuli WHERE i klauzuli HAVING s kritérii pro pole, která nejsou použita v agregačních funkcích uvedených v klauzuli WHERE, a podmínky pro pole, která se používají v agregačních funkcích v klauzuli HAVING.
Další informace o klauzuli HAVING najdete v článku Klauzule HAVING.
Operátor UNION se používá k zobrazení všech dat vrácených více podobnými vybranými dotazy současně jako zřetězená sada.
Operátor UNION vám umožňuje kombinovat dva příkazy SELECT do jednoho. Sloučené příkazy SELECT musí mít stejný počet a pořadí výstupních polí se stejnými nebo kompatibilními datovými typy. Když spustíte dotaz, data z každé sady odpovídajících polí se spojí do jednoho výstupního pole, takže výstup dotazu má stejný počet polí jako každý příkaz SELECT jednotlivě.
Poznámka: V sjednocovacích dotazech jsou kompatibilní číselné a textové datové typy.
Pomocí operátoru UNION můžete určit, zda mají být do výsledků dotazu zahrnuty případné duplicitní řádky. Chcete -li to provést, použijte klíčové slovo ALL.
Dotaz kombinující dva příkazy SELECT má následující základní syntaxi:
VYBRAT pole_1
Z tabulky_1
SVAZ
VYBERTE pole_a
Z tabulky_a
;
Předpokládejme například, že máte dvě tabulky s názvem „Produkty“ a „Služby“. Obě tabulky obsahují pole s názvem produktu nebo služby, informacemi o ceně a záruce a také pole, které označuje exkluzivitu nabízeného produktu nebo služby. Přestože v tabulkách Produkty a služby existují různé typy záruk, základní informace jsou stejné (existuje záruka kvality pro jednotlivé produkty nebo služby). Pomocí následujícího dotazu na spojení můžete zkombinovat čtyři pole ze dvou tabulek:
VYBRAT název, cena, záruka_k dispozici, exkluzivní_ nabídka
Z produktů
UNION ALL
VYBRAT název, cena, záruka_k dispozici, exkluzivní_ nabídka
OD SLUŽEB
;
Další informace o kombinování příkazů SELECT pomocí operátoru UNION najdete v článku
Základní příkazy SQL by měl znát každý programátor
SQL nebo Structured Query Language se používá k manipulaci s daty v systému relační databáze (RDBMS). Tento článek bude hovořit o běžně používaných příkazech SQL, které by měl znát každý programátor. Tento materiál je ideální pro ty, kteří chtějí oprášit své znalosti SQL před pracovním pohovorem. Chcete -li to provést, analyzujte příklady uvedené v článku a pamatujte si, čím jste prošli ve dvojicích v databázích.
Některé databázové systémy vyžadují na konci každého příkazu středník. Středník je standardní ukazatel na konec každého příkazu v SQL. Příklady používají MySQL, takže je vyžadován středník.
Vytvořte databázi, která předvede, jak týmy fungují. Chcete -li fungovat, musíte si stáhnout dva soubory: DLL.sql a InsertStatements.sql. Poté otevřete terminál a zadejte konzolu MySQL následujícím příkazem (tento článek předpokládá, že MySQL je již v systému nainstalován):
MySQL -u root -p
Poté zadejte heslo.
Spusťte následující příkaz. Nazvěme databázi „univerzitou“:
VYTVOŘIT DATABÁZU univerzita; USE univerzita; ZDROJ Může být nutné vytvořit omezení pro konkrétní sloupce v tabulce. Při vytváření tabulky můžete nastavit následující omezení: Lze zadat více než jeden primární klíč. V tomto případě získáte složený primární klíč. Vytvořte tabulku „instruktor“: Instruktor CREATE TABLE (ID CHAR (5), jméno VARCHAR (20) NOT NULL, dept_name VARCHAR (20), plat NUMERIC (8,2), PRIMARY KEY (ID), FOREIGN KEY (dept_name) REFERENCES department (dept_name)); Různé informace (typ hodnoty, klíč nebo ne) o sloupcích tabulky můžete zobrazit pomocí následujícího příkazu: POPSAT Při přidávání dat do každého sloupce tabulky není nutné zadávat názvy sloupců. VLOŽ DO SELECT se používá k načítání dat z konkrétní tabulky: VYBRAT Následující příkaz může zobrazit všechna data z tabulky: VYBRAT * OD Sloupce tabulky mohou obsahovat duplicitní data. Pomocí SELECT DISTINCT získáte pouze neduplicitní data. VYBERTE ROZDÍL Klíčové slovo WHERE v SELECT můžete použít k zadání podmínek v dotazu: VYBRAT V žádosti lze specifikovat následující podmínky: Zkuste následující příkazy. Věnujte pozornost podmínkám uvedeným v KDE: SELECT * FROM course WHERE dept_name = 'Comp. Sci. '; VYBRAT * Z kurzu KDE kredity> 3; VYBRAT * Z kurzu KDE dept_name = "Comp. Sci." A kredity> 3; Klauzule GROUP BY se často používá k agregaci výstupních hodnot s agregačními funkcemi, jako jsou COUNT, MAX, MIN, SUM a AVG. VYBRAT Ukažme počet kurzů pro každou fakultu: VYBERTE POČET (ID_kurzu), název_deptU Z SKUPINY PODLE JMÉNA_sept; Klíčové slovo HAVING bylo přidáno do SQL, protože WHERE nelze použít s agregačními funkcemi. VYBRAT Pojďme uvést fakulty s více než jedním kurzem: VYBRAT POČET (id_kurzu), název_deptU Z kurzu SKUPINA PODLE názvu_odboru MAJÍCÍ POČET (kurz_id)> 1; ORDER BY se používá k řazení výsledků dotazů v sestupném nebo vzestupném pořadí. ORDER BY bude řadit vzestupně, pokud není zadán žádný způsob řazení ASC nebo DESC. VYBRAT Ukažme si seznam kurzů vzestupně a sestupně podle počtu kreditů: VYBRAT * Z kurzu OBJEDNÁVKA PODLE kreditů; VYBRAT * Z kurzu OBJEDNÁVAT PODLE kreditů DESC; BETWEEN se používá k výběru hodnot dat ze zadaného rozsahu. Lze použít číselné a textové hodnoty i data. VYBRAT Zde je seznam instruktorů, jejichž plat je vyšší než 50 000, ale nižší než 100 000: VYBERTE * OD instruktora KDE mzda MEZI 50 000 A 100 000; Operátor LIKE se používá v WHERE k určení vzoru hledání pro podobnou hodnotu. LIKE používají dva bezplatné operátory: Ukažme si seznam kurzů, jejichž název obsahuje „to“, a seznam kurzů, jejichž název začíná na „CS-“: VYBRAT * Z kurzu KDE název LIKE '% to%'; VYBRAT * Z kurzu KDE kurz_id LIKE "CS -___"; Pomocí IN můžete zadat více hodnot pro klauzuli WHERE: VYBRAT Ukažme si seznam studentů z Comp. Sci. Fyzika a Elec. Angličtina: VYBRAT * OD studenta KDE VSTUP název odd. ('Comp. Sci.', 'Physics', 'Elec. Eng.'); JOIN se používá k propojení dvou nebo více tabulek pomocí společných atributů v nich. Následující obrázek ukazuje různé způsoby kombinování v SQL. Všimněte si rozdílu mezi levým vnějším spojením a pravým vnějším spojením: VYBRAT Zobrazí se seznam všech kurzů a odpovídající informace o fakultách: VYBERTE * Z PŘIPOJENÍ kurzu oddělení ZAPNUTO course.dept_name = department.dept_name; Pojďme uvést všechny požadované kurzy a podrobnosti o nich: VYBRAT prereq.course_id, název, název_odboru, kredity, prereq_id OD PRÉVY LEFT OUTER JOIN kurz ON prereq.course_id = course.course_id; Pojďme zobrazit seznam všech kurzů bez ohledu na to, zda jsou povinné nebo ne: VYBRAT course.course_id, title, dept_name, kredites, prereq_id FROM prereq RIGHT OUTER JOIN kurz ON prereq.course_id = course.course_id; View je virtuální tabulka SQL vytvořená spuštěním výrazu. Obsahuje řádky a sloupce a je velmi podobný běžné tabulce SQL. Zobrazit vždy zobrazuje nejnovější informace z databáze. Vytvořme pohled sestávající z kurzů se 3 kredity: Tyto funkce se používají k získání souhrnného výsledku souvisejícího s danými daty. Následující jsou běžně používané agregační funkce: Vnořené poddotazy jsou dotazy SQL, které obsahují klauzule SELECT, FROM a WHERE vnořené v rámci jiného dotazu. Pojďme najít kurzy, které byly vyučovány na podzim 2009 a na jaře 2010: VYBERTE ROZDÍL kurzu_id OD sekce WHERE semestr = „Podzim“ A rok = 2009 A ID kurzu IN (VYBERTE předmět_ID OD sekce KDE semestr = „Jaro“ A rok = 2010); Pokud jste jako já, pak budete souhlasit: SQL je jednou z věcí, které se na první pohled zdají snadné (čte se jako v angličtině!), Ale z nějakého důvodu musíte každý jednoduchý dotaz vygooglit, abyste našli správnou syntaxi. A pak se připojí, začnou agregace, poddotazy a dopadne to úplně jako nesmysl. Vypadá to takto: Bue! To vyděsí každého nováčka nebo dokonce středně pokročilého vývojáře, pokud toto poprvé vidí SQL. Ale není to tak špatné. Je snadné si zapamatovat, co je intuitivní, a s pomocí tohoto tutoriálu doufám, že snížím vstupní prahovou hodnotu SQL pro nováčky a pro ty, kteří již mají zkušenosti, nabídnout nový způsob pohledu na SQL. Ačkoli je syntaxe SQL v různých databázích téměř stejná, tento článek používá pro dotazy PostgreSQL. Některé příklady budou fungovat v MySQL a dalších databázích. V SQL je mnoho klíčových slov, ale SELECT, FROM a WHERE se objevují téměř v každém dotazu. O něco později si uvědomíte, že tato tři slova představují nejzákladnější aspekty vytváření databázových dotazů a další, složitější dotazy jsou pouze doplňky. Podívejme se na databázi, kterou použijeme jako příklad v tomto článku: Máme knihovnu a lidi. Existuje také speciální tabulka pro účtování vydaných knih. Začněme jednoduchým dotazem: potřebujeme jména a identifikátory(id) všech knih napsaných autorem "Dan Brown" Žádost bude vypadat takto: A výsledek je takový: Docela jednoduché. Podívejme se na žádost, abychom pochopili, co se děje. Nyní se to může zdát zřejmé, ale FROM bude velmi důležité později, až se dostaneme ke spojením a poddotazům. FROM ukazuje na tabulku, proti které se chcete dotazovat. Může to být existující tabulka (jako ve výše uvedeném příkladu) nebo tabulka vytvořená za běhu prostřednictvím spojení nebo poddotazů. WHERE se chová jako filtr strunyže chceme výstup. V našem případě chceme vidět pouze ty řádky, kde hodnota ve sloupci autora je „Dan Brown“. Nyní, když máme všechny potřebné sloupce z tabulky, kterou potřebujeme, musíme se rozhodnout, jak tato data zobrazit. V našem případě jsou potřeba pouze názvy a identifikátory knih, takže toto a my Vybrat pomocí SELECT. Současně můžete sloupec přejmenovat pomocí AS. Celý dotaz lze zobrazit pomocí jednoduchého diagramu: Nyní chceme vidět názvy (ne nutně jedinečné) všech knih Dana Browna, které byly převzaty z knihovny, a kdy je třeba tyto knihy vrátit: Výsledek: Z větší části je požadavek podobný předchozímu. s výjimkou OD sekcí. Znamená to, že požadujeme data z jiné tabulky... Nepristupujeme k tabulce knih ani k tabulce výpůjček. Místo toho odkazujeme na nový stůl který vznikl spojením dvou tabulek. půjčky PŘIPOJTE se k knihám ON LOVINGS.bookid = books.bookid je nová tabulka, která byla vytvořena kombinací všech záznamů z tabulek "knihy" a "výpůjčky", ve kterých jsou hodnoty knih stejné. Výsledkem takového sloučení bude: A pak dotazujeme tuto tabulku stejným způsobem jako v příkladu výše. To znamená, že při spojování tabulek si musíte dělat starosti jen s tím, jak toto spojení vytvořit. A pak je žádost jasná jako v případě „jednoduché žádosti“ z bodu 3. Zkusme trochu složitější spojení dvou tabulek. Nyní chceme získat jména lidí, kteří převzali z knihovny autorské knihy „Dan Brown“. Tentokrát pojďme zdola nahoru: Krok Krok 1- odkud získáváme data? Abychom dosáhli požadovaného výsledku, musíme spojit tabulky „členské“ a „knihy“ s tabulkou „výpůjčky“. Sekce PŘIPOJENÍ bude vypadat takto: Výsledek připojení je vidět na odkazu. Krok 2- jaká data zobrazujeme? Zajímají nás pouze údaje, kde je autorem knihy „Dan Brown“ Krok 3- jak data zobrazujeme? Nyní, když byla data přijata, stačí zobrazit jméno a příjmení těch, kteří si knihy vzali: Super! Zbývá pouze zkombinovat tři komponenty a vytvořit požadavek, který potřebujeme: Co nám dá: Pokuta! Jména se ale opakují (nejsou jedinečná). Brzy to napravíme. Zhruba řečeno, agregace jsou potřebné k převodu více řádků do jednoho... Současně se při agregaci používá pro různé sloupce odlišná logika. Pokračujme v našem příkladu, kde se objevují duplicitní jména. Je vidět, že Ellen Horton si půjčila více než jednu knihu, ale není to nejlepší způsob, jak tyto informace ukázat. Lze podat další žádost: Což nám poskytne požadovaný výsledek: Téměř všechny agregace mají klauzuli GROUP BY. Tato věc změní tabulku, kterou lze načíst pomocí dotazu, na skupiny tabulek. Každá skupina odpovídá jedinečné hodnotě (nebo skupině hodnot) pro sloupec, který jsme zadali v GROUP BY. V našem příkladu převádíme výsledek z předchozího cvičení do skupiny řádků. Agregujeme také s count, který převádí více řádků na celočíselnou hodnotu (v našem případě je to počet řádků). Poté je tato hodnota přiřazena každé skupině. Každý řádek ve výsledku je výsledkem agregace každé skupiny. Můžete dojít k logickému závěru, že všechna pole ve výsledku by měla být uvedena buď ve SKUPINĚ BY, nebo by na nich měla být provedena agregace. Protože všechna ostatní pole se mohou navzájem lišit v různých řádcích a pokud je vyberete pomocí SELECT, není jasné, které z možných hodnot je třeba vzít. Ve výše uvedeném příkladu funkce count zpracovala všechny řádky (protože jsme počítali počet řádků). Ostatní funkce jako součet nebo max zpracovávají pouze zadané řetězce. Pokud například chceme zjistit počet knih napsaných jednotlivými autory, potřebujeme dotaz takto: Výsledek: Zde funkce součet zpracovává pouze sloupec zásoby a vypočítá součet všech hodnot v každé skupině. Poddotazy jsou běžné dotazy SQL vložené do větších dotazů. Jsou rozděleny do tří typů podle typu vráceného výsledku. Existují dotazy, které vracejí více sloupců. Dobrým příkladem je dotaz z posledního agregačního cvičení. Jako poddotaz jednoduše vrátí další tabulku, proti které lze vytvářet nové dotazy. Pokud budeme pokračovat v předchozím cvičení, chceme -li zjistit počet knih napsaných autorem „Robin Sharma“, pak je jednou z možných cest použití poddotazů: Výsledek: Lze zapsat jako: [„Robin Sharma“, „Dan Brown“] 2. Nyní použijme tento výsledek v novém dotazu: Výsledek: To je stejné jako: Existují dotazy, jejichž výsledkem je pouze jeden řádek a jeden sloupec. Lze s nimi zacházet jako s konstantními hodnotami a lze je použít kdekoli, kde se používají hodnoty, například ve srovnávacích operátorech. Mohou být také použity jako dvourozměrné tabulky nebo jednoprvková pole. Pojďme například získat informace o všech knihách v knihovně, jejichž počet je v tuto chvíli nad průměrem. Průměr lze získat takto: Což nám dává: Většina zápisů do databáze je ve srovnání se složitějšími čteními poměrně jednoduchá. Syntaxe pro dotaz UPDATE je sémanticky stejná jako pro dotaz pro čtení. Jediným rozdílem je, že místo výběru sloupců SELECT nastavíme hodnoty SET. Pokud jsou ztraceny všechny knihy Dana Browna, musíte obnovit hodnotu množství. Žádost bude vypadat takto: KDE dělá to samé jako dříve: vybere řádky. Namísto SELECT, který byl použit při čtení, nyní používáme SET. Nyní však musíte ve vybraných řádcích zadat nejen název sloupce, ale také novou hodnotu pro tento sloupec. Dotaz DELETE je pouze dotazem SELECT nebo UPDATE bez názvů sloupců. Vážně. Stejně jako u SELECT a UPDATE zůstává klauzule WHERE stejná: vybírá řádky, které mají být odstraněny. Operace odstranění zničí celý řádek, takže nemá smysl zadávat samostatné sloupce. Pokud se tedy rozhodneme neresetovat počet knih Dana Browna, ale úplně smazat všechny záznamy, můžeme podat následující požadavek: Snad jediná věc, která se liší od ostatních typů dotazů, je VLOŽIT. Formát je: Kde a, b, c jsou názvy sloupců a x, y a z jsou hodnoty, které mají být vloženy do těchto sloupců, ve stejném pořadí. To je v podstatě vše. Podívejme se na konkrétní příklad. Zde je dotaz INSERT, který naplní celou tabulku „books“: Došli jsme na konec, navrhuji malý test. Podívejte se na tuto žádost na samém začátku článku. Dokážete na to přijít? Zkuste to rozdělit na klauzule SELECT, FROM, WHERE, GROUP BY a zvažte jednotlivé komponenty poddotazů. Tady je to v čitelnější podobě: Tento dotaz vrátí seznam lidí, kteří si rezervovali knihu z knihovny, která má nadprůměrný součet. Výsledek: Doufám, že jste to bez problémů zvládli. Ale pokud ne, ocenil bych vaše komentáře a zpětnou vazbu, abych mohl tento příspěvek vylepšit.Příkazy databáze
1. Zobrazte dostupné databáze
ZOBRAZIT DATABÁZE; 2. Vytvoření nové databáze
VYTVOŘIT DATABÁZI; 3. Výběr databáze k použití
POUŽITÍ 4. Import příkazů SQL ze souboru .sql
ZDROJ 5. Odebrání databáze
DROP DATABASE Práce s tabulkami
6. Prohlížení tabulek dostupných v databázi
UKÁZAT TABULKY; 
7. Vytvoření nové tabulky
VYTVOŘIT TABULKU Omezení integrity pomocí CREATE TABLE
Příklad
8. Tabulka informace

9. Přidání dat do tabulky
VLOŽ DO 10. Aktualizace dat tabulky
AKTUALIZACE 11. Odebrání všech dat z tabulky
ODSTRANIT OD 12. Odstranění tabulky
DROP TABLE Příkazy pro zadávání požadavků
13. VYBERTE

14. VYBERTE ROZDÍL

15. KDE
Příklad

16. SKUPINA PODLE
Příklad

17. MÁM
Příklad

18. OBJEDNÁVKA PODLE
Příklad

19. MEZI
Příklad

20. LIKE
VYBRAT Příklad

21. IN
Příklad

22. PŘIPOJTE SE

Příklad 1

Příklad 2

Příklad 3

23. Pohled
Tvorba
VYTVOŘIT POHLED Mazání
DROP VIEW Příklad

24. Agregační funkce
25. Vnořené poddotazy
Příklad

Potřebujete „VYBRAT * KDE a = b OD c“ nebo „VYBRAT KDE a = b OD c ZAPNOUT *“?
SELECT members.firstname || "" || members.lastname AS "Full Name" Z výpůjček VNITŘNÍ PŘIPOJTE se členové NA Members.memberid = půjčky.memberid VNITŘNÍ PŘIPOJTE knihy NA books.bookid = půjčky.bookid KDE půjčky.bookid IN (VYBRAT bookid Z knih KDE skladem> (VYBR. prům. ) Z knih)) SKUPINA PODLE členů.křestní jméno, členové.název; 1. Tři kouzelná slova
2. Naše základna


3. Jednoduchý požadavek
VYBERTE bookid jako "id", název Z knih KDE autor = "Dan Brown"; id
titul
2
Ztracený symbol
4
Peklo
3.1 OD - odkud získáváme data
3.2 KDE - jaké údaje zobrazit
3.3 VÝBĚR - jak zobrazit data

4. Připojení (spojení)
VYBRAT books.title AS "Název", půjčky.returndate AS "Datum vrácení" Z výpůjček PŘIPOJTE knihy K půjčkám.bookid = books.bookid WHERE books.author = "Dan Brown"; Titul
Datum návratu
Ztracený symbol
2016-03-23 00:00:00
Peklo
2016-04-13 00:00:00
Ztracený symbol
2016-04-19 00:00:00

půjčky PŘIPOJTE SE K ONLINE knihy ONLINGS.
WHERE books.author = "Dan Brown"
VYBERTE members.firstname AS "First Name", members.lastname AS "Last Name"
VYBERTE members.firstname AS "First Name", members.lastname AS "Last Name" Z výpůjček PŘIPOJTE se k knihám ON pôžičky.bookid = books.bookid PŘIPOJTE se k členům ON Members.memberid = půjčky.memberid KDE books.author = "Dan Brown"; Jméno
Příjmení
Mike
Willis
Ellen
Horton
Ellen
Horton
5. Agregace
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count (*) AS "Počet vypůjčených knih" Z výpůjček PŘIPOJTE se k knihám NA půjčky.bookid = books.bookid PŘIPOJTE se k členům NA Members.memberid = výpůjčky .memberid KDE books.author = "Dan Brown" SKUPINA PODLE členů.firstname, members.lastname; Jméno
Příjmení
Počet vypůjčených knih
Mike
Willis
1
Ellen
Horton
2
VYBRAT autora, součet (zásoby) Z knih SKUPINA PODLE autora; autor
součet
Robin sharma
4
Dan hnědý
6
John green
3
Amish tripathi
2
6. Poddotazy

6.1 Dvojrozměrná tabulka
VYBRAT * OD (VYBRAT autora, součet (zásoby) Z knih SKUPINA PODLE autora) JAKO výsledky KDE autor = "Robin Sharma";
VYBRAT název, bookID Z knih KDE je autor IN (SELECT author FROM (SELECT author, sum (stock) FROM books GROUP BY author) AS results WHERE sum> 3); titul
bookid
Ztracený symbol
2
Kdo bude plakat, když zemřete?
3
Peklo
4
VYBRAT název, kniha Z knih, KDE JE VSTUP autor („Robin Sharma“, „Dan Brown“); 6.3 Jednotlivé hodnoty
vyberte průměr (sklad) z knih; 7. Operace zápisu
7.1 Aktualizace
AKTUALIZOVÁNO knihy SET stock = 0 KDE autor = "Dan Brown"; 7.2 Odstranit
ODSTRANIT Z knih KDE autor = "Dan Brown"; 7.3 Vložit
VLOŽTE DO x (a, b, c) HODNOTY (x, y, z);
VLOŽTE DO knih (bookid, název, autor, publikováno, skladem) HODNOTY (1, „Scion of Ikshvaku“, „Amish Tripathi“, „06-22-2015“, 2), (2, „The Lost Symbol“, „ Dan Brown “,„ 07-22-2010 “, 3), (3,„ Kdo bude plakat, když zemřete? “,„ Robin Sharma “,„ 06-15-2006 “, 4), (4,„ Peklo “ , „Dan Brown“, „05-05-2014“, 3), (5, „The Fault in our Stars“, „John Green“, „01-03-2015“, 3); 8. Ověření
SELECT members.firstname || "" || members.lastname AS "Full Name" Z výpůjček VNITŘNÍ PŘIPOJTE se členové NA Members.memberid = půjčky.memberid VNITŘNÍ PŘIPOJTE knihy NA books.bookid = půjčky.bookid KDE půjčky.bookid IN (VYBRAT bookid Z knih KDE skladem> (VYBR. prům. ) Z knih)) SKUPINA PODLE členů.křestní jméno, členové.název; Celé jméno
Lida tyler










